PIM, díl 5: A proč zrovna “chytrý” produktový katalog?
Proč používáme termín “chytrý” produktový katalog? Hodně už jsme naznačili minule. Jednoduchá databáze může popsat nabídku jednoduchého e-shopu. Ale na složitý e-shop, jehož nabídka se neustále mění, nebo dokonce na popis produktů banky či telekomunikačního operátora – na to už potřebujeme plnohodnotný modelační nástroj. Tady už nestačí jen držet seznam nabízených produktů. Je potřeba nad těmito produkty taky dělat nějakou rozumnou logiku. A co je ještě důležitější, tuhle logiku je potřeba v čase měnit a přizpůsobovat novým produktům a novým očekáváním zákazníků. Proto je důležité, jestli tuhle logiku musí naprogramovat programátor, nebo si ji může naklikat produkťák sám.
Proč je tak důležité, aby produktovou logiku mohl spravovat produkťák bez pomoci programátorů? Tři dobré důvody: cena, rychlost, nezávislost.
- Když produkťák musí svůj nápad zformulovat do zadání a předat programátorovi, stojí je to oba mnohonásobně víc času. A jak známo, čas jsou peníze. Pokud naopak produkťák nemusí psát zadání a programátor ho nemusí studovat, ušetří oba dva spoustu času na užitečnější věci. Produkťák sám své myšlenky nakonfiguruje přímo v produktovém katalogu, sám si je vyzkouší a otestuje, sám si opraví chyby a za chvíli už publikuje nové produkty zákazníkům. A když za pár týdnů zjistí, že produkt na zákazníky nefunguje tak, jak má, tak si produkt sám upraví, logiku pozmění a zkusí to jinak.
- Žádná firma nemá tým programátorů okamžitě připravených chopit se zadání a začít dělat. Programátoři mají svou frontu úkolů stejně jako kdokoli jiný. Takže zadání od produkťáka bude v té frontě nějakou dobu čekat. Zpracovaná změna od programátora bude potom zase čekat na otestování produkťákem. A potom se zase čeká na programátora kvůli opravě chyb. Všechny tyhle kroky výrazně prodlužují time-to-market – dobu mezi okamžikem, kdy produkťák vymyslí skvělý nový produkt, a okamžikem, kdy se tenhle produkt konečně dostane na trh k zákazníkům. Jenomže konkurence nespí. A pokud přijde se stejným nápadem rychleji než my, tak nám zákazníky sebere.
- Když změny logiky systému implementuje programátor, stává se na něm firma závislou. Je celkem jedno, jestli jde o závislost na externím dodavateli (vendor-lock) nebo o závislost na interním programátorovi s absurdními nápady jako je měsíční dovolená v Jižní Americe. Naproti tomu, pokud je logika produktového katalogu uložená v konfiguraci, kterou umí spravovat sami produkťáci, může ji snadno měnit jakýkoliv nový produkťák. K tomu je samozřejmě důležité, aby konfigurace byla jednoduchá, přehledná a srozumitelná. Pokud bude konfigurace logiky hodně komplexní, tak už ji rovnou můžeme nechat programátorům.
Jednoduché pravidlo zní “Pokud to produkťák umyslí, tak si to i nakonfiguruje.” Definice produktů, jejich parametry, i kalkulace ceny, to jsou věci, které vymýšlejí produkťáci a sami by tedy měli mít možnost si je zadat a měnit. Naopak třeba integraci s externími systémy už produkťák nevymyslí – takže je jednodušší ji nechat programátorům. (S hlubokou omluvou těm produkťákům, kteří píšou básně v JSON a na pivní tácek si čmárají XSL transformace 😉 )
Pojďme se tedy podívat, jak se dá logika v produktovém katalogu jednoduše konfigurovat. Různé PIM systémy se k této potřebě staví různým způsobem. Mnohé ji v podstatě ignorují a implementují jen takovou logiku, která je potřeba pro základní využití v jednoduchém e-shopu. Pokročilejší systémy umožňují konfigurování produktové logiky pomocí parametrů nebo pravidel. A jak je tahle chytrost udělaná konkrétně ve WisePorteru?
Na nejjednodušší úrovni se dá využít toho, že chování WisePorteru je do velké míry řízené informacemi, které jsou v katalogu. Může jít například o číselníky nebo o vztahy produktů. Obojí může měnit administrátor systému – typicky vyškolený produkťák. A tím může zároveň měnit chování systému. Jak je to možné? Je to dané tím, že WisePorter je v jádru modelovací systém. Takže i základní model (to, že existují produkty v nějaké hierarchii) se dá změnit a upravit. Nebo, častěji, vhodně rozšířit.
Druhá, zajímavější úroveň řízení produktové logiky spočívá ve využití takzvané rule engine. Jedná se o nástroj, který umí vyhodnocovat pravidla. Pravidel existuje několik různých druhů (vzorce, rozhodovací tabulky, atd.) a můžou vypadat různě – třeba jako excelová tabulka. Tabulka má několik vstupních polí, ve kterých dostane parametry, a jedno nebo více výstupních polí, ve kterých odevzdá výsledek. V čem spočívá síla takové rule engine? V jednoduchosti popisu pravidel a v jejich vyhodnocení za běhu.
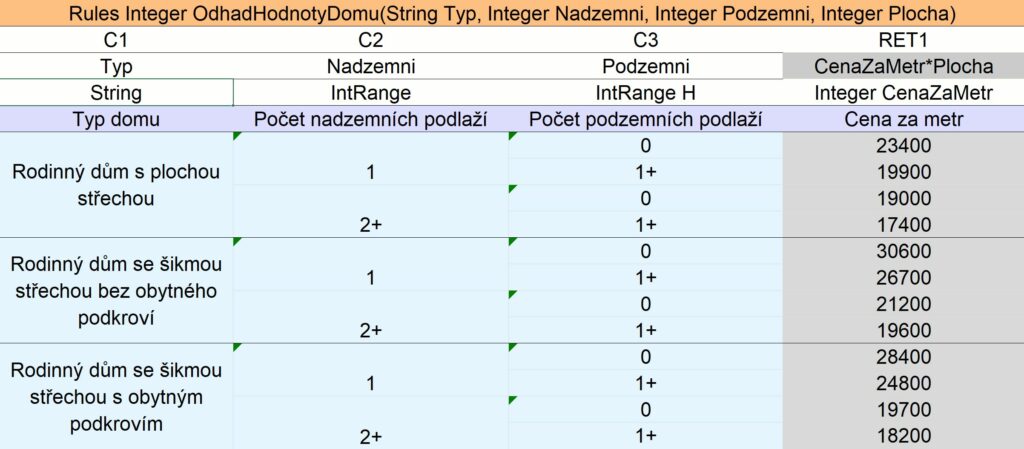
Jednoduchost rule engine je daná tím, že pravidla lze opravdu zadat jako excelovou tabulku. Není potřeba nic programovat ani učit produkťáky syntaxi nějakého speciálního skriptovacího jazyka. Udělat výpočetní tabulku v Excelu zvládne skoro každý. Prohlédněte si příklad na připojeném obrázku – asi budete souhlasit, že tuhle kalkulaci by po krátkém vysvětlení dokázal upravit i člen strany Důchodců za Životní Jistoty. A jakmile takovou tabulku máme, můžeme ji naimportovat do rule engine a používat ve WisePorteru pro výpočty a rozhodování za běhu.
Jak to vypadá v praxi? Řekněme, že děláme on-line platformu, která nabízí hypotéky. Klient zadá základní parametry: odhadovanou hodnotu nemovitosti, kolik potřebuje půjčit a jak dlouho chce splácet. Z CRM systému dostaneme ještě další informace – například věk klienta a jeho credit rating. Všechny tyhle informace tvoří vstup WisePorteru. WisePorter vyhledá ve své databázi všechny hypotéční produkty a ke každému z nich jeho pravidlo pro výpočet. Pro každý hypotéční produkt zavolá relevantní pravidlo připravené v rule engine a předá mu vstupní parametry. Od každého pravidla dostane vypočítanou výši splátek. Tyhle výsledky setřídí a vrátí (některé z nich) pro zobrazení klientovi.
Že na tom není nic převratného? Ne, opravdu není. Ta převratná věc je skrytá pod povrchem a proběhla už mnohem dříve. Ta převratná věc spočívá v tom, že celý tenhle proces byl připravený bez zásahu programátora. Obchodní tým vymyslel sérii hypotéčních produktů. Jeden člověk vytvořil v excelu kalkulace pro všechny produkty, tyhle kalkulace nějak pojmenoval a nahrál do rule engine. Druhý člověk zadal produkty do katalogu a ke každému z nich zadal název kalkulace v rule engine. Dva businessoví lidi bez sebemenší znalosti programování zadali během pár hodin do systému sadu hypotéčních produktů, které se můžou okamžitě začít nabízet klientům. Tohle je převratné, protože tenhle proces ve většině bank zahrnuje IT projekt a trvá měsíce. Tady jsme time-to-market snížili o dva řády. A tohle je důvod, proč WisePorter nazýváme chytrým produktovým katalogem a proč se vymyká z běžné koncepce PIM systémů.
 O týmu WisePorter: Karel Krema má v týmu WisePorter na starosti produktový model. Svou práci popisuje takto: “Denně se z praxe učím, jak údaje zpracovávané v procesech našich klientů co nejpřesněji zachytit v datovém modelu. Dobře zvládnutý model je jedním z hlavních klíčů k úspěchu, s ním vše stojí a padá. Musí se dobře navrhnout už na začátku, kdy je ještě hodně požadavků neznámých. A velmi těžko se později mění. Modelování musí realitu popisovat co nejvěrněji. Uživatelům se pak s výsledkem pracuje snadno a intuitivně. A pouze model, který vychází z dobře pochopených business principů, bez problémů ustojí i změny a nové požadavky v budoucnu.“
O týmu WisePorter: Karel Krema má v týmu WisePorter na starosti produktový model. Svou práci popisuje takto: “Denně se z praxe učím, jak údaje zpracovávané v procesech našich klientů co nejpřesněji zachytit v datovém modelu. Dobře zvládnutý model je jedním z hlavních klíčů k úspěchu, s ním vše stojí a padá. Musí se dobře navrhnout už na začátku, kdy je ještě hodně požadavků neznámých. A velmi těžko se později mění. Modelování musí realitu popisovat co nejvěrněji. Uživatelům se pak s výsledkem pracuje snadno a intuitivně. A pouze model, který vychází z dobře pochopených business principů, bez problémů ustojí i změny a nové požadavky v budoucnu.“



